SLTAの言語情報処理 Part6:『読む』の言語情報処理
SLTAの言語情報処理Part6、今回は『読む』の言語情報処理です。
認知神経心理学的モデルは、これまでと同様に下記の画像をご参照ください。
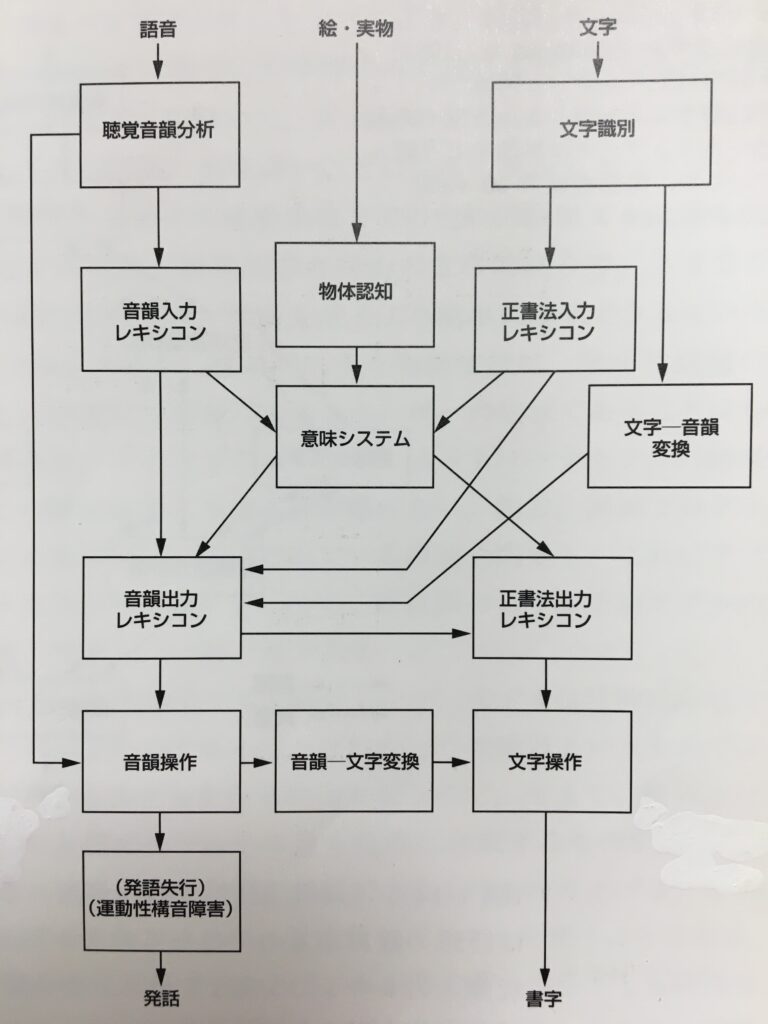
語彙ルート・・・主に漢字単語の理解
絵・実物→物体認知→意味システム
文字→文字識別→正書法入力レキシコン→意味システム
漢字単語は主に語彙ルートですが、このあとに紹介する音韻ルートももちろん使われています。
しかし、例えば「時計」を「じけい」や「ときけい」などと頭の中で読まないのは、私たちが頭の中で語彙として捉えているという証明になります。
熟字訓(例 田舎「いなか」)は完全に語彙ルートのみの使用です。
音韻ルート・・・主に仮名単語の理解
絵・実物→物体認知→意味システム
文字→文字識別→文字-音韻変換→音韻入力レキシコン→意味システム
仮名単語でも例えば「うどん」のように表記妥当性の高いものは語彙ルートで処理されます。
障害過程としては、まず、文字識別(文字の形態認知)の段階で統覚型視覚失認による影響があり得ます。
その後は、語彙照合や意味照合での誤りが考えられますが、(漢字やかな)文字が提示されているため、文字が音や意味のヒントとなり、聴覚的理解の課題より成績が向上することがあります。
また、仮名単語の理解は、文字-音韻変換が必要となってくるため、文字を対応する音韻に正確に変換できないと誤りが生じます。
以上、『読む』の言語情報処理に関してみていきました。
