SLTAの言語情報処理 Part2:『聞く』の言語情報処理
今回は、SLTAの言語情報処理 第2弾『聞く』編のPart1です。
今回も下の認知神経心理学的モデルを参照してください。
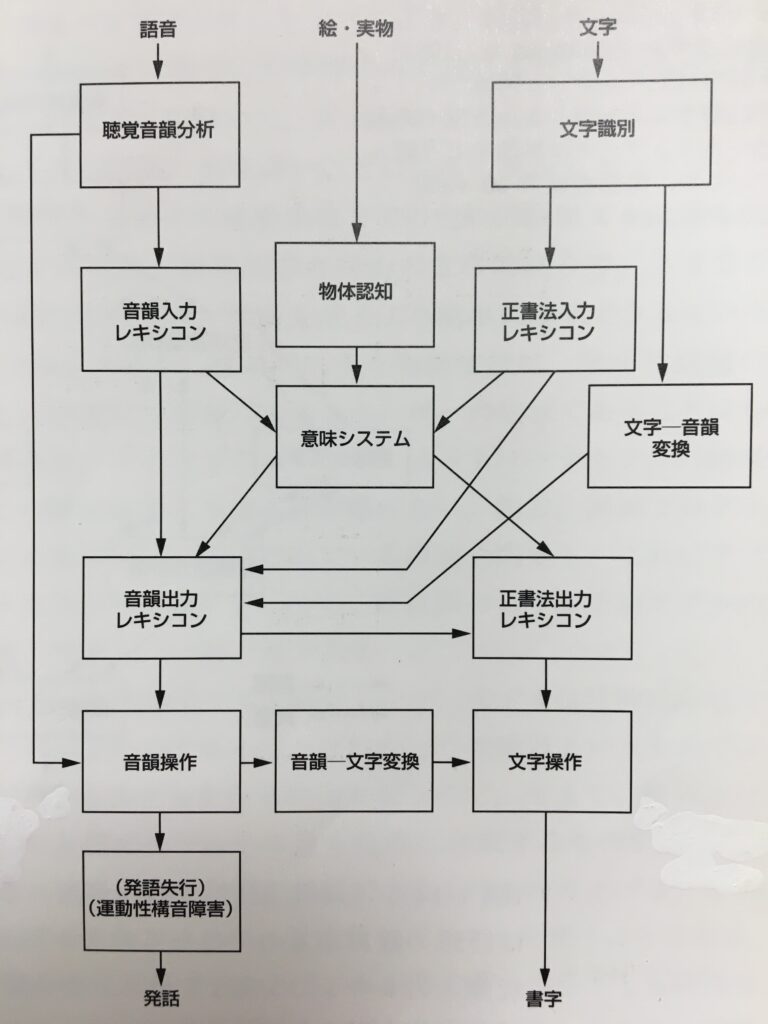
SLTAの『聞く』の検査項目は、『単語の理解』、『短文の理解』、『口頭命令に従う』、『仮名の理解』がありますね。
認知神経心理学的モデル(以下、モデルと呼びます)は単語レベルの処理を前提としていますので、このなかで『単語の理解』と『仮名の理解』をピックアップします。
『短文の理解』や『口頭命令に従う』は文レベルの処理になりますので、単語レベルの処理が一通り終わってから、書いていきます。
【単語の理解】
まず、絵を見て、それが何か認識する必要があります。
モデルでは、絵・実物→物体認知→意味システムに当たります。
例えば、『猫』の絵を見て、まず、それが『猫』だとわかる必要があります。
次に、検査者が発する語音を聞いて、その意味合いを認識します。
モデルでは、語音→聴覚音韻分析→音韻入力レキシコン→意味システムに当たります。
例えば、[neko]と語音を聞いて、それが「ねこ」と日本語の音韻としてわかり、さらに「猫」という語彙だとわかり、最後にあの『猫』のことだなと、その意味合いまでわかります。
この2つの過程ができて、はじめて語音を聞いてその絵を指さすことができるわけです。
【仮名の理解】
まず、文字(記号)を見て、日本語の文字だとわかり、その文字を音韻に変換できる必要があります。
モデルでは、文字→文字識別→文字-音韻変換に当たります。
例えば、『か』という記号を見て、日本語の「か」という文字だとわかり、日本語の音韻にすると「か」のことだなと、その読み方までわかります。
次に、聞いた語音を日本語の音韻として認識します。
モデルでは、語音→聴覚音韻分析に当たります。
例えば、[ka]と聞いて、日本語の音韻である「か」だとわかります。
この2つの過程ができて、はじめて語音を聞いてその文字を指さすことができるわけです。
以上、認知神経心理学的モデルを用いて、『聞く』の言語情報処理が正しくできた場合をみていきました。
次回は、『聞く』の障害過程についてみていきます。
